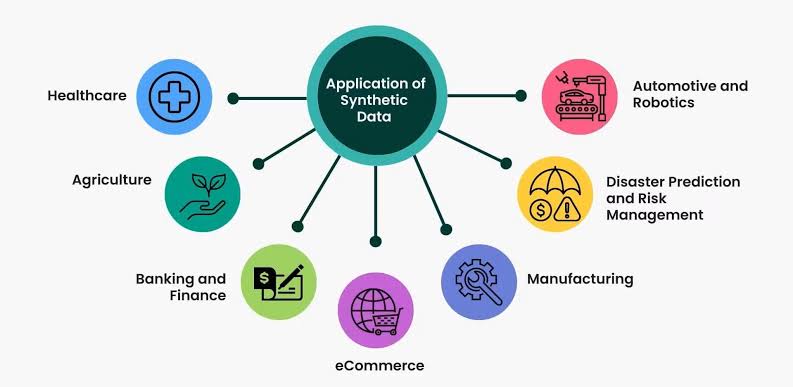
Synthetic data refers to information that is artificially generated rather than collected from real-world events. It mimics the statistical properties and structure of actual data but is created using algorithms, simulations, or generative models.
Unlike anonymized or masked data, which originates from real datasets, synthetic data is born entirely from computational models. This means it can be created without involving any actual people or sensitive records, making it a powerful tool for data privacy.
In 2025, synthetic data is gaining widespread use in sectors where data access is restricted or where privacy regulations like GDPR and HIPAA limit the use of real data. Its ability to replicate real-world conditions while eliminating privacy risks has positioned it as a transformative asset.
The Technology Behind Synthetic Data Generation
The process of generating synthetic data has evolved rapidly in recent years. Today, it primarily involves the use of machine learning, deep learning, and statistical modeling.
Generative Adversarial Networks (GANs), a type of deep learning model, are commonly used to produce highly realistic synthetic data. GANs work by pitting two neural networks against each other—one generating data and the other evaluating its authenticity—until the output becomes indistinguishable from real data.
In other cases, rule-based simulators are used to model complex systems such as weather patterns, financial markets, or traffic flows. This versatility makes synthetic data applicable to a wide variety of use cases, from images and video to tabular and time-series data.
Ensuring Data Privacy and Security
One of the primary motivations for using synthetic data is to protect privacy. Since the data is not linked to real individuals, the risk of revealing personal information is significantly reduced.
This is especially relevant in 2025, where data privacy laws have become even stricter globally. Organizations must demonstrate not only secure data handling but also transparency in how data is used and shared.
Synthetic data offers a legal and ethical workaround. For example, hospitals can train AI models on synthetic patient records without risking exposure of private health details. Similarly, banks can test fraud detection systems using simulated transaction data instead of actual customer accounts.
Enhancing AI and Machine Learning Models
Synthetic data is playing a crucial role in training artificial intelligence and machine learning models. In many cases, real-world data is limited, biased, or imbalanced—problems that synthetic data can help address.
For instance, a self-driving car algorithm may require millions of driving scenarios, including rare events like a child suddenly running into the street. Collecting enough real examples of such scenarios would be both difficult and ethically questionable. Synthetic simulations allow these edge cases to be safely and abundantly produced.
In 2025, AI developers routinely use synthetic data to augment real datasets, especially in areas like facial recognition, speech analysis, and robotics. This improves model accuracy, robustness, and fairness.
Applications in Healthcare
The healthcare sector is one of the biggest beneficiaries of synthetic data. Medical research often involves sensitive information that cannot be shared freely, even for innovation or collaboration.
With synthetic data, researchers can generate datasets that retain the patterns and relationships of real patient information without violating privacy laws. This opens the door for developing diagnostic tools, treatment algorithms, and personalized medicine without compromising patient trust.
In July 2025, several healthcare providers in North America and Europe are already using synthetic medical data to train AI models for early detection of diseases like cancer and diabetes.
Applications in Finance and Banking
In finance, synthetic data is used to simulate customer behaviors, create fraud scenarios, and stress-test algorithms under different market conditions. This helps financial institutions improve services while meeting regulatory standards.
Credit scoring models, for example, benefit from synthetic data by modeling diverse borrower profiles that may not exist in the available historical data. This helps improve access to credit for underrepresented groups.
As of 2025, banks also use synthetic data to train chatbots and virtual assistants, allowing them to interact more effectively with customers without needing access to real transaction histories.
Improving Software Testing and Quality Assurance
Synthetic data is invaluable in software testing environments. Developers can simulate a wide range of user interactions, edge cases, and system failures without having to rely on production data.
This accelerates the development cycle and helps identify bugs and vulnerabilities before software is released to the public. It also reduces the legal risks associated with using sensitive data during testing.
Companies in 2025 are increasingly adopting synthetic data to test applications in sectors such as insurance, e-commerce, and logistics, where customer interactions are frequent and varied.
Limitations and Ethical Considerations
Despite its advantages, synthetic data is not without limitations. If the underlying data generation model is flawed, the synthetic data may also carry inaccuracies or biases. This can lead to poor model performance or misleading conclusions.
Moreover, synthetic data is not a perfect substitute for real data in all situations. Certain nuances—especially those based on human behavior—can be difficult to replicate accurately.
Ethical considerations also arise when synthetic data is used in scenarios like law enforcement or surveillance. Just because data is artificial doesn’t mean its use is automatically fair or unbiased. Developers must ensure that synthetic datasets are created responsibly and validated rigorously.
The Future of Synthetic Data
The synthetic data market is growing rapidly. Analysts predict it will exceed $2.5 billion USD by 2027, with increasing adoption in AI development, enterprise analytics, and academic research.
New tools are emerging that allow non-technical users to generate synthetic datasets through user-friendly interfaces. Cloud platforms are also beginning to offer synthetic data as a service, making it more accessible to startups and smaller organizations.
In July 2025, governments and institutions are even exploring the use of synthetic data in national statistics and urban planning, leveraging its potential to simulate population behavior without infringing on individual rights.
Conclusion: Unlocking the Potential of Synthetic Data
Synthetic data is no longer a futuristic concept—it’s a present-day solution to some of the most pressing challenges in data science, privacy, and innovation. By mimicking real-world data without exposing sensitive information, it offers a powerful tool for ethical, scalable, and secure development.
As of July 2025, its applications span from healthcare and finance to education, retail, and beyond. While it must be used thoughtfully and validated properly, synthetic data holds the promise of accelerating innovation without compromising privacy or integrity.
For businesses, researchers, and governments alike, understanding and embracing synthetic data could be the key to building smarter, safer, and more inclusive systems for the future.